Physics-Based Single-Image Super-Resolution for MRI
From self-supervised enhancement to generative-prior recovery
Background
Clinical MRI is often acquired as stacks of 2D slices rather than fully isotropic 3D volumes. This can reduce scan time, improve signal-to-noise ratio, and enable useful clinical contrasts, but it creates anisotropic images with thick slices, slice gaps, and degraded views in the through-plane direction. These acquisitions are useful for visual interpretation, but anisotropy can impair automated 3D analysis, registration, segmentation, and quantitative measurements.
Many deep learning super-resolution methods use paired low- and high-resolution images to train a feed-forward network that maps one image directly to another. That formulation can work well when paired training data match the deployment setting, but clinical MRI rarely provides clean pairs across scanners, protocols, contrasts, resolutions, and patient populations. Our lab instead develops MRI super-resolution methods that use information available within the scan itself or impose explicit image-formation constraints. The goal is to recover higher-resolution 3D anatomy from real-world clinical images while preserving fidelity to the measured image and improving downstream usability.
ECLARE: Self-Supervised Super-Resolution
ECLARE, or “Efficient Cross-planar Learning for Anisotropic Resolution Enhancement”, is a self-supervised super-resolution method for anisotropic multislice MRI. It first estimates the through-plane slice profile from the input volume using a method like ESPRESO, which gives an image-specific degradation model rather than assuming an idealized blur kernel. ECLARE then creates its own training pairs from the same scan by degrading high-resolution, in-plane patches to match the lower-resolution through-plane direction. A neural network learns this low-to-high-resolution mapping within the image and is then applied to the through-plane direction to recover a higher-resolution volume.
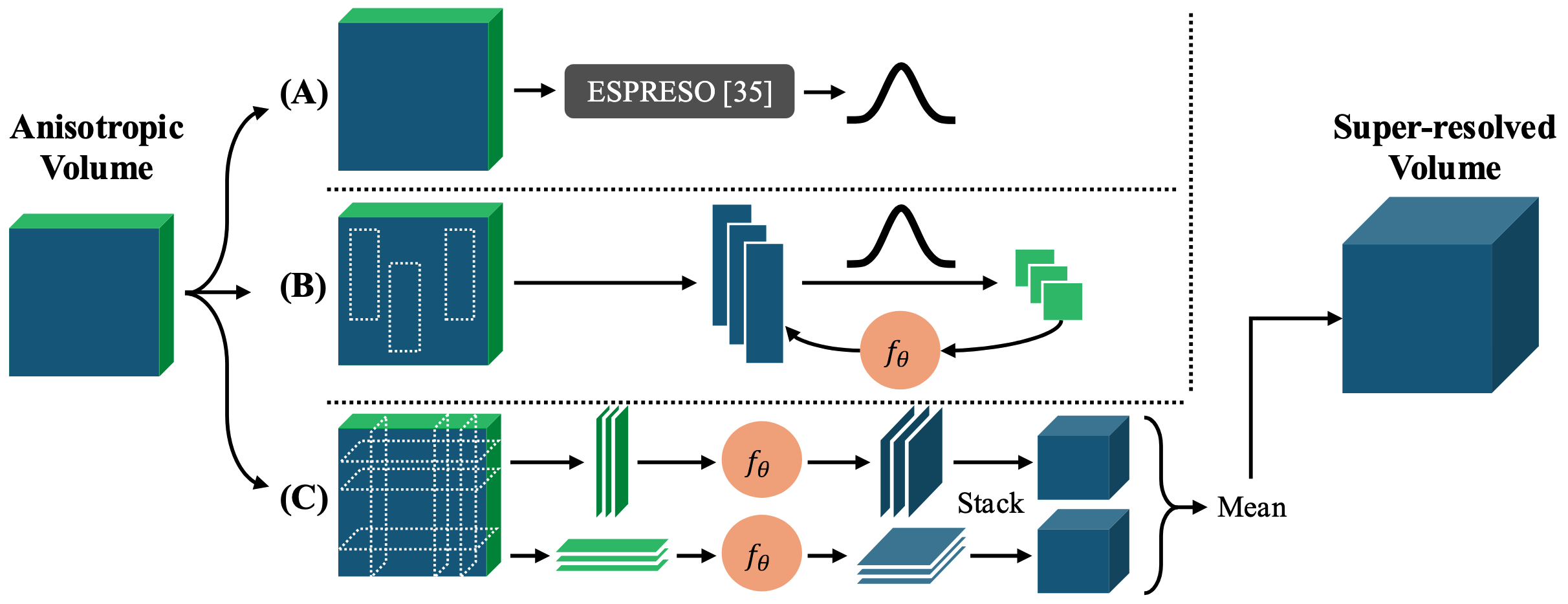
Because ECLARE is self-supervised and trains from the image being enhanced, it does not require external paired high-resolution training data. This is useful for heterogeneous clinical imaging, where scanner protocol, contrast, resolution, pathology, and population differences can create domain shift between training and testing data. The subject-specific training also lets the method adapt to uncommon protocols or contrasts without requiring a separate model for each acquisition setting.
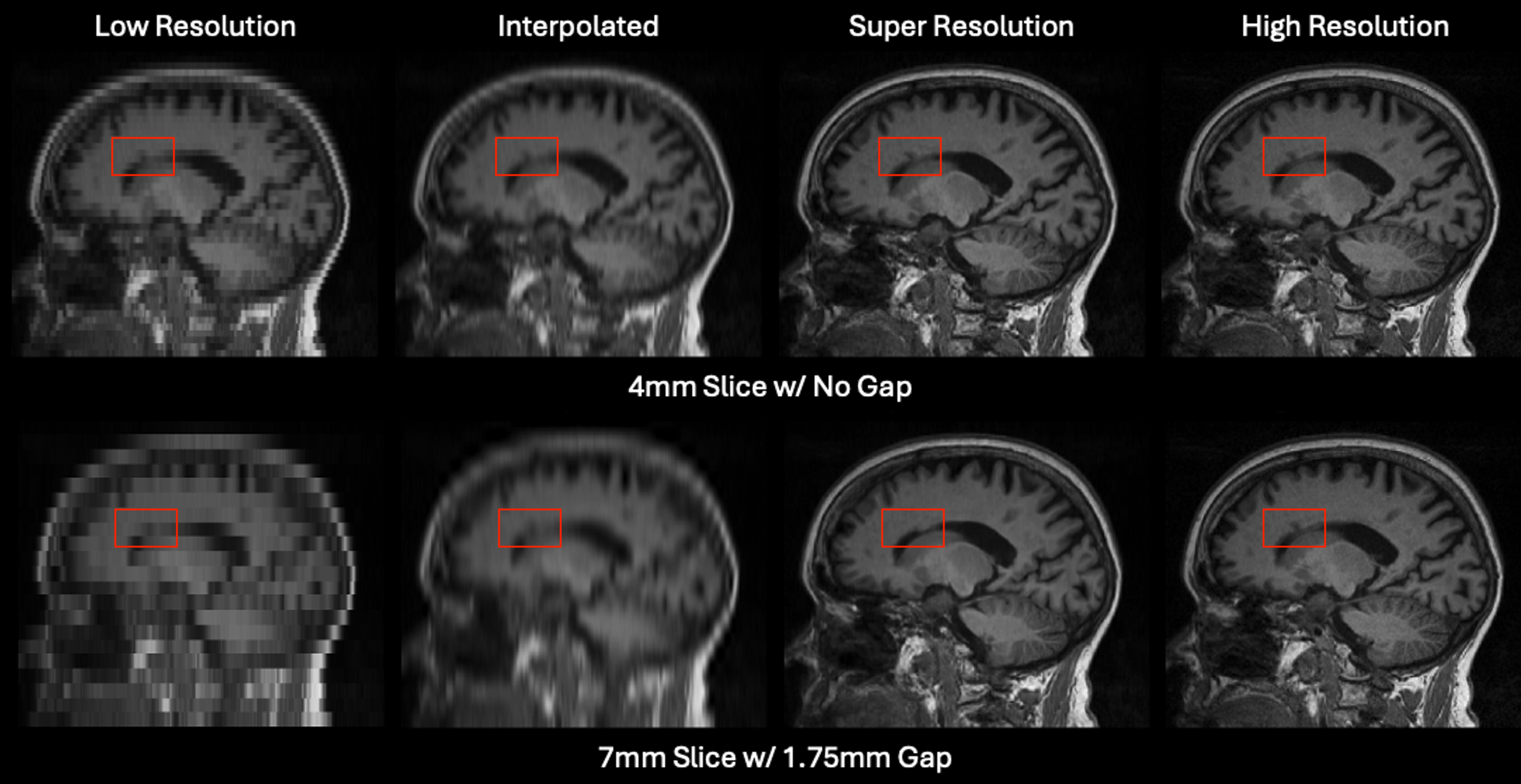
ECLARE was designed to address practical issues that many MRI super-resolution methods ignore, including slice profile shape, slice gaps, domain shift, field-of-view preservation during resampling, anti-aliasing, and arbitrary or non-integer upsampling factors. In simulation experiments with ground truth, ECLARE improved signal recovery and downstream task performance compared with interpolation, previous self-supervised methods such as SMORE, and other contemporary super-resolution methods. On real anisotropic MRI, where ground truth is usually unavailable, the method is evaluated through qualitative image recovery and downstream processing behavior.
FOCVS: Cycle-Consistent Zero-Shot Super-Resolution with Generative Priors
Single-image super-resolution is limited by the information available in one anisotropic acquisition. Our newer work treats through-plane super-resolution as an inverse problem: the high-resolution image should look anatomically plausible, but when degraded by the acquisition model it should also reproduce the measured low-resolution image.
FOCVS, or “Forward Operator Consistent Volumetric Super-Resolution”, uses a zero-shot, scan-specific optimization strategy for anisotropic head MRI. Instead of training a supervised model on external low-resolution/high-resolution pairs, the method reconstructs a high-resolution image that is both realistic under an image prior and cycle-consistent with the observed anisotropic scan after simulated degradation. This cycle-consistency constraint is important because it prevents the super-resolved image from drifting away from the measured data while still allowing missing through-plane information to be regularized by the prior.
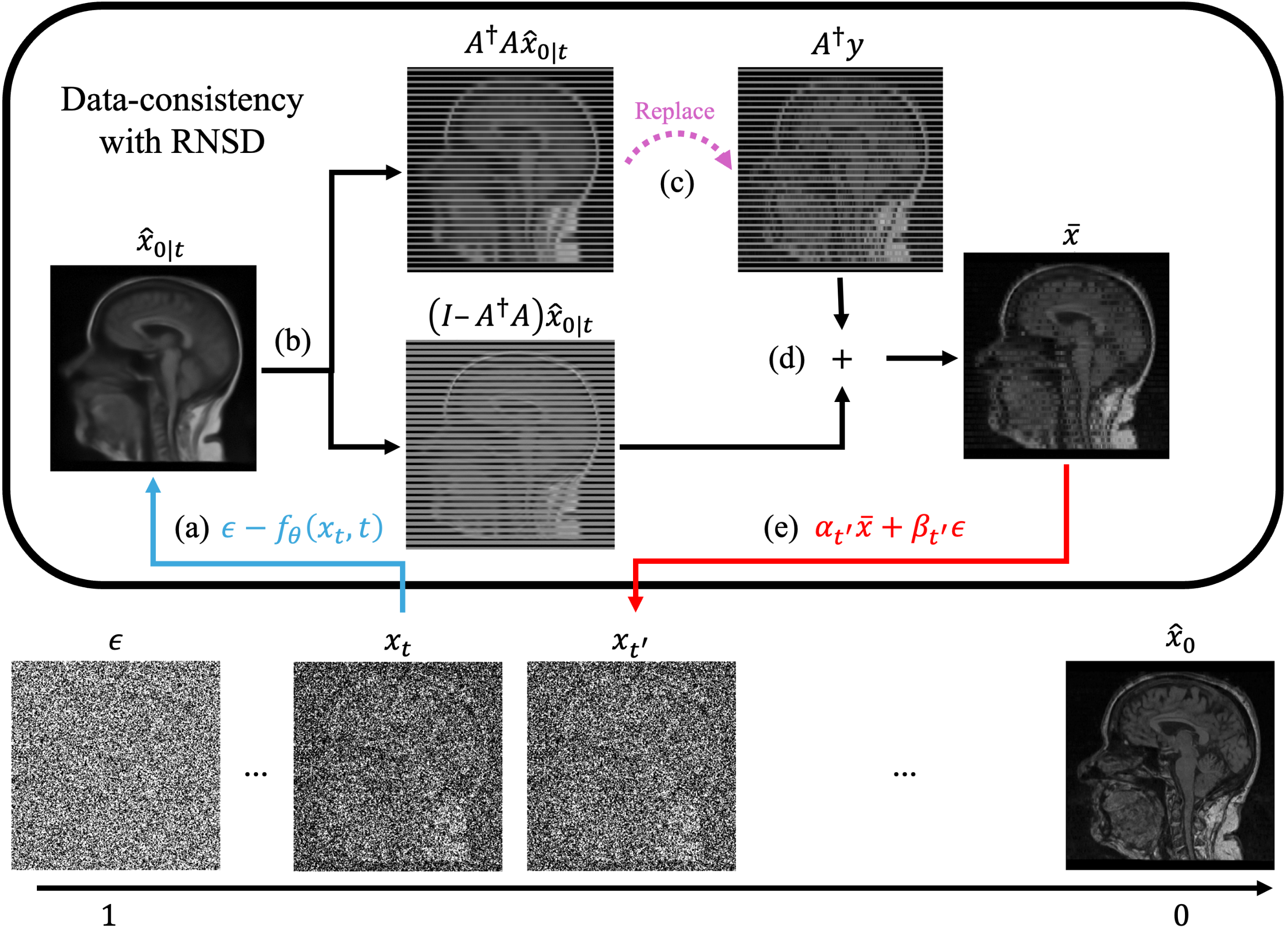
This work moves single-image MRI super-resolution from purely feed-forward or self-supervised patch-learning methods toward forward-model-aware generative inference. The target is not only sharper-looking images, but reconstructions that remain compatible with the image formation model and are useful for downstream 3D analysis.
Code and Papers
ECLARE: Efficient Cross-planar Learning for Anisotropic Resolution Enhancement
Cycle-Consistent Zero-Shot Through-Plane Super-Resolution for Anisotropic Head MRI
Paper / Code Coming Soon